MIT 6.null Lecture Notes
Lecture 1 Shell
bash中如果想提供一个包含空格的参数,可以用‘或"“把它们引起来,或者用转义字符\,比如My\ Photos来将空格转义
$PATH是环境变量,即在本地文件夹下没有找到对应可以执行的程序时会自动在环境变量的路径中寻找相应的程序。which提示了能够运行本指令的程序路径,比如~$ which echo /bin/echols -l表示以详细方式列出当前文件夹下的文件missing:~$ ls -l /home drwxr-xr-x 1 missing users 4096 Jun 15 2019 missing第1个字符表明这个文件的类型。d表示这是一个文件夹,如果是-表示这是一个普通文件,l表示这是一个链接文件,类似于windows下的快捷方式,b表示这是一个块设备文件,一般置于/dev目录下,没有文件大小,只有一个主设备号和辅设备号。块设备是一次传输一整块数据的设备,比如硬盘。c表示这是一个字符设备文件,一般置于/dev目录下,字符设备是一次只传输一个字符数据的设备,比如键盘。p表示这是一个命令管道文件,与shell编程有关,s表示这是一个socks文件,与shell编程有关
d后面有3*3个标志,表示不同的身份对该文件的权限。r表示可读权限,w表示可写权限,x表示可执行权限,-表示无相应权限。第一组表示该文件的所有者的权限,第二组表示文件所有者同组用户的权限,第三组表示其他用户的权限
权限后面的第一个数字表示1. 当这是一个文件时,为硬连接数,即有几个文件硬链接到了这个文件 2. 当这是一个文件夹时,为链接占用的节点,即该目录中包含的子目录的个数
对于一个文件夹来说,为了进入这个文件夹,必须拥有"search"权限,也就是拥有对这个文件夹以及其所有父路径文件夹的x权限。为了
ls这个文件夹,必须拥有这个文件夹的r权限重定向输入输出流:
< file将输入设定为文件,> file将结果输出到文件,原先文件的内容会被覆盖missing:~$ echo hello > hello.txt missing:~$ cat hello.txt hello missing:~$ cat < hello.txt hello missing:~$ cat < hello.txt > hello2.txt missing:~$ cat hello2.txt hello>>可以来向文件附加数据。|是管道符号,可以将前一个命令的输出作为下一个命令的输入。curl --head --silent google.com | grep --ignore-case content-length | cut --delimiter=' ' -f2 # 查看向google发送HTTP GET请求的头文件中的content length属性的值文件描述符:一般情况下每个unix命令运行时都会打开3个文件:
- 标准输入文件(stdin):文件描述符为0,unix默认从stdin输入数据
- 标准输出文件(stdout):文件描述符为1,unix默认向stdout输出数据
- 标准错误文件(stderr):文件描述符为2,unix会向stderr流中写入错误消息
默认情况下,
command>file将stdout重定向到file,command<file将stdin重定向到filecommand 2>>file # 将stderr追加到文件末尾///dev/null文件是一种特殊的文件,写入到它的内容都会被丢弃,也无法从中读取到任何内容,如果希望执行某个命令,但是不希望在屏幕上显示输出结果,可以将输出重定向到/dev/null
command >> /dev/null 2>&1 # 屏蔽stdout和stderrcommand >> /dev/null已经将标准输出重定向,2>&1中的&表示等同,2>表示错误输出,2>&1表示错误输出重定向的对象等同于标准输出重定向的对象,即/dev/nullsysfs:Linux内核下基于内存的文件系统,可以将很多内核参数以文件形式暴露,从而可以方便地修改kernel。比如笔记本电脑的屏幕亮度可以以文件的形式在sys/class/backlight下被暴露$ sudo find -L /sys/class/backlight -maxdepth 2 -name '*brightness*' /sys/class/backlight/thinkpad_screen/brightness $ cd /sys/class/backlight/thinkpad_screen $ sudo echo 3 > brightness # permission denied,因为>重定向符号之前的sudo并不能被后面观察到,也就是说写入brightness这个操作实际上并没有执行sudo $ echo 3 | sudo tee brightness # success,tee这个命令是获取标准输入,将内容输出成文件,并将其打印到屏幕上chmod(change mode)来控制用户对文件的权限的命令。只有文件拥有者(owner)和超级用户(super user)可以修改文件或者目录的权限chmod [-cfvR] [--help] [--version] mode file... # mode格式为 [ugoa...][[+-=][rwxX]...][,...] # u表示该文件的拥有者,g表示与该文件的拥有者属于同一个group者,o表示其他人,a表示这三者皆是 # +表示增加权限,-表示取消权限,=表示唯一设定权限 # r表示可读取,w表示可写入,x表示可执行,X表示只有当该文件是个子目录或者该文件已经被设定过为可执行 # 示例:将file1.txt设定为所有人皆可读取 chmod ugo+r file1.txt也可以采用八进制的方法来规定权限
# 权限 rwx 二进制 7 读+写+可执行 rwx 111 6 读+写 rw- 110 5 读+执行 r-x 101 4 只读 r– 100 3 写+执行 -wx 011 2 只写 -w- 010 1 只执行 –x 001 0 无 — 000 # file1.txt这个文件对所有的用户均可读可写可执行 chmod 777 file1.txt # file2.txt这个文件对其他用户只可执行 chmod ug=rwx,o=x file2.txt # 与以下相同 chmod 771 fil2.txt一般比较常用的是
chmod 755和chmod 777shebang:
#!写在脚本的第一行,用来规定该脚本的解释器。
#!后接解释器的绝对路径。比如想要规定这个脚本用sh来执行,那么在第一行添加#!/bin/sh推荐使用
/usr/bin/env python来规定该脚本解释器,这是因为env会在$PATH中查找python解释器的安装位置,这样可以不用提供一个解释器的绝对路径,从而提高程序的可移植性后台执行shell
在shell命令的最后一个位置加
&
Lecture 2 Shell Tools and Scripting
Shell Scripting
Shell是一个用C语言编写的程序,是一种解释性语言。Windows Explorer是一个典型的图形界面shell
Bourne Shell /bin/sh或/usr/bin/sh
Bourne Again Shell /bin/bash
给变量赋值:
注意在定义变量时变量名不加美元符号,变量名和等号之间不能有空格。在使用一个已经定义过的变量时需要加美元符号
foo=bar # 注意不能是foo = bar,否则bash会认为这是运行了foo命令,并以=和bar作为参数传入 echo "$foo" # prints bar echo '$foo' # or echo "${foo}" # 花括号加不加可选,主要是为了清晰变量名的边界 # prints $foo # 注意在bash中"和‘是不同的。在'中$变量不会被替换,"中$后面的变量会被替换为其值readonly变量是只读变量,不能被赋值myurl="www.fanxiao.tech" readonly myurl使用
unset命令可以删除变量获取字符串的长度
string="abcd" echo ${#string} # 输出4提取子字符串
从字符串的第2个字符开始截取四个字符
string="runoob is a great site" echo ${string:1:4} # 输出unoo函数
# 以shell脚本的名称创建一个文件夹并cd到这个文件夹中 mcd(){ mkdir -p "$1" cd "$1" }$0:脚本本身的名称$1-$9:脚本的第1-第9个参数$@:所有脚本的参数$#:脚本参数的个数$?:前一个命令的返回代码$$:当前脚本的PID!!:完整的上一个命令,包括参数。如果一个命令只是因为没有root权限失败,则可以执行sudo !!来重新执行该命令$_:上一个命令的最后一个参数
数组
数组索引从0开始。用括号()来表示数组,数组元素用空格分开。定义数组的一般形式为
数组名=(值1 值2 值3 值4)
如
array_name=(value0 value1 value2)还可以单独定义数组的各个分量,如
array_name[0]=1读取数组元素值的方式是
$(数组名[下标]),使用@则可以获取数组中的所有元素,例如echo ${array_name[@]}获取数组的长度的方法是
length=${array_name[@]}bash基本运算
原生bash不支持简单的数学运算,但是可以通过其他命令实现,比如
exprval=`expr 2 + 2` # 注意:表达式和运算符之间一定要有空格,例如2+2是不对的,必须写成2 + 2,注意不是单引号而是反引号 echo "两数之和为$val" # 输出为"两数之和为4"条件表达式要放在方括号之间,并且要有空格,例如
if [$a == $b] then echo "a等于b" fi if [$a != $b] then echo "a不等于b" fi关系运算符:
运算符 说明 -eq 检测两个数是否相等,相等则返回true -ne 检测两个数是否不等,不等则返回true -gt 检测左边的是否大于右边的,大于则返回true -lt 检测左边的是否小于右边的,小于则返回true -ge 检测左边的是否大于等于右边的,大于等于则返回true -le 检测左边的是否小于等于右边的,小于等于则返回true ! 非运算 -o 或运算 -a 与运算 注意:乘号前必须要加上反斜杠\转义才是乘法运算
test命令可以用于检查某个条件是否成立# 数值测试 num1=100 num2=200 if test $[num1] -eq $[num2] then echo '两个数相等' else echo '两个数不相等' fi # 文件测试 cd /bin if test -e ./bash then echo '文件存在' else echo '文件不存在' fi注意:新的test
[[]]比旧的test[]更好,尽量使用[[]]流程控制:shell编程的流程控制不可为空,即
if和else的代码块里必须执行一定的动作将
if和else写成一行的方法:if [ $(ps -ef | grep -c "ssh") -gt 1]; then echo "true"; fi # 查找当前所有进程中ssh进程的个数,如果大于1则返回truefor循环的一般格式for var in item1 item2 ... itemN do command1 command2 commandN done写成一行:
for var in item1 item2 itemN; do command1; command2; commandN; done;while循环:int=1 while [ $int -lt 5 ] do echo $int let "int++" # let是bash中用于计算的工具,变量计算中不需要加上$表示变量 done # 运行结果 # 1 # 2 # 3 # 4 # 5case选择每个case分支从右圆括号开始,用两个分号
;;表示break,跳出整个case...esac语句echo '输入1到4之间的数字' echo '你输入的数字为' read aNum case $aNum in 1) echo '你选择了1' ;; 2) echo '你选择了2' ;; 3) echo '你选择了3' ;; 4) echo '你选择了4' ;; *) echo '你没有输入1到4之间的任何数字' ;; esacbreak命令while true do echo -n "输入1到5之间的数字" read aNum case $aNum in 1|2|3|4|5) echo "你输入的数字为$aNum!" ;; *) echo "你输入的数字不是1到5之间的!结束" break ;; esac doneshell函数
[function] funname [()] { action [return int] } # example demoFun(){ echo "第一个shell函数" } demoFun # 调用这个函数程序的返回值:执行成功返回0,执行失败则返回其他大小的数值。注意,和C语言不同,shell中0表示true,1表示false
获取一个程序的变量值,如
$(CMD)会先执行CMD,获取CMD的输出并再相应位置进行替换。比如执行for file in $(ls),将先执行ls,然后遍历执行ls后获得的返回值进程替换(process substitution):
<(CMD)将执行CMD,然后将结果输出到一个临时文件,并把<()替换为这个文件名。比如cat <(ls -l)相当于ls -l | cat,diff <(CMD1) <(CMD2)是比较这两个CMD的区别shell文件包含
包含外部脚本,以封装一些公用的代码作为一个独立文件
. file # 注意.和文件名中间有一个空格 # 或者 source fileshell通配符(globbing)
wildcard: 使用
*或?来进行匹配,比如有foo1、foo2、foo几个文件,rm foo?将删除foo1和foo2,而rm foo*将删除foo1、foo2和foo等三个文件花括号
{用来扩展子字符串convert image.{png,jpg} # will expand to convert image.png image.jpg
Shell Tools
tldr: – too long, didn’t read manual cheat sheet for console
寻找文件
find# 寻找所有名为src的文件夹 find . -name src -type d # 寻找所有路径名中有test文件夹的Python文件 find . -path '*/test/*.py' -type f # 寻找所有在昨天被修改的文件 find . -mtime -l # 寻找所有大小在500k到10M的zip文件 find . -size +500k -size -10M -name '*.tar.gz' # 删除所有.tmp扩展名的文件。-exec表示在find寻找到这些文件之后可以执行的额外动作,\;表示这些额外动作的结束。{}用来指代前面find到的文件 find . -name '*.tmp' -exec rm {} \; # 将所有PNG文件转化为JPG文件 find . -name '*.png' -exec convert {} {}.jpg \;fd是更好的find,支持正则表达式查找locate是一个使用updatedb更新的数据库进行文件查找的程序,效率比find和fd更高,但是因为是每日更新的,所以并不是最新的。grep是基于文件内容进行搜索,grep -C是获取匹配内容的上下文(Context),比如grep -C 5是获取匹配内容的上下各5行内容,grep -R是递归(Recursively)地进入文件夹查找文件中的内容,grep -v用来反向(inversely)选择匹配的内容rg、ag等也是和grep类似的查找工具,其中ripgrep(rg)是一个查找神器,用来查找代码中的code snippet,可以进行自动递归搜索,自动故忽略.gitignore中的文件和二进制文件,例如rg -t py "import request"查找所有包含
import request的python文件history可以用来查看shell中的所有交互记录,history | grep find则可以打印出过去曾经使用的find命令在shell中可以按CTRL+R来进行反向搜索历史,通过键入一个子字符串来搜索过去的命令
fzf是一个模糊搜索工具(fuzzy finder)zsh:一种非常牛逼的shell,可以实现根据历史的命令来进行自动命令建议fasd是快速跳转路径的工具,可以根据访问频率来自动给出跳转路径的建议
Lecture 3 Vim
快捷键
- normal mode下G: 跳转到文件的最后一行
gg跳转到文件的第一行- w:下一个word,bbeginning of word、e:end of word
- $:跳转到行尾,^跳转到行首
- ^u:向上滚动 ^d:向下滚动
- h:光标左移 j:光标下移 k:光标上移 l:光标右移
:sp file:水平方向分割窗口,并打开file:vsp file:垂直方向分割窗口,并打开file^ww:在打开的分割窗口之间切换
- /:搜索字符串,按n跳转到下一个匹配,按N跳转到上一个匹配,可以进行
/{regex}正则表达式搜索 - c:change,即删掉选中的字符,然后进入Insert模式
- d:delete,即删掉选中的字符
- u:undo ^r: redo
- v:进入visual模式,可以通过光标移动来进行文本块的选择
- .:重复之前的键入
- o(open):在下方键入新行
:n:跳转到第n行:%d:删除所有行,其中%表示所有行:2,8d表示删除第2到第8行- modifier: i(inside)或a(around),比如
ci[就是删除[]内的所有字符并进入insert模式,ca(就是删除()内以及()本身这些所有的字符并且进入insert模式 - counts: 在命令前面加上数字来表示重复动作,比如
3w是向后跳转3个word,5j是向下跳转5行
插件推荐
CtrlP: 一种能够在vim中模糊查找工程文件的vim插件
fugitive.vim: vim的git插件
ale:code linting插件,需要先安装pylint和eslint等linting插件
sudo apt-get install vim-gtk:系统自带vim不支持复制到系统剪切板,需要重装vim
可以安装vim-airline这款主题美化插件 NERDTree目录树,在vim normal模式键入:NERDTree即可打开目录树,:q关闭目录树
在/etc/vim/vimrc最后增加以使vim使用系统剪切板
" WSL yank support
let s:clip = '/mnt/c/Windows/System32/clip.exe' " change this path according to your mount point
if executable(s:clip)
augroup WSLYank
autocmd!
autocmd TextYankPost * if v:event.operator ==# 'y' | call system(s:clip, @0) | endif
augroup END
endif
Lecture 4 Data Wrangling
RegEx
+表示前面的字符必须出现一次或者多次*表示前面的字符可以出现0次、1次或者多次?表示前面的字符可以出现0次或1次,加在+和*后面以实现非贪婪匹配[abc]表示匹配其中的所有abc三个字符[^abc]表示匹配除了a、b、c之外的其他所有字符[A-Z]表示一个区间,匹配所有大写字母[\s]匹配所有空白符[\S]匹配所有非空白符,[\s\S]匹配所有字符[\d],digit,匹配[0-9]的数字,[\D]匹配所有非数字.匹配除了换行符\n之外的所有字符[\w]word,匹配字母、数字、下划线,等价于[a-zA-Z0-9_]()标记一个子表达式的开始和结束位置,子表达式可以获取供以后使用非捕获元:
?:放在()中可以避免匹配被缓存,exp1(?=exp2)正向肯定预查,查找exp2前的exp1,(?<=exp2)exp1查找exp2后的exp1,exp1(?!exp2)查找后面不是exp2的exp1,(?<!exp2)exp1查找前面不是exp2的exp1 只有grep -P才支持{}限定符表达式,用来表示匹配的长度,比如s{1,3}表示匹配1-3个空格,o{1,}表示匹配1个以上的o^:定位符,匹配输入字符串开始位置,不要和中括号表达式中的^混淆。$:定位符,匹配输入字符串结束位置\b:定位符,匹配单词边界\B:定位符,匹配非单词边界修饰符:写在正则表达式之外,用于指定额外的匹配策略
\pattern\flagsi-ignore,不区分大小写g-global,查找所有的匹配项m-multiline,多行匹配,使^和$匹配一段文本中每行的开始和结束位置
use case
获取尝试连接远程服务器的用户名
ssh myserver 'journalctl | grep sshd | grep "Disconnected from"' | less # journalctl是日志管理工具 journalctl和from之间的''quoting是为了直接在服务器来查找这些内容,再把筛选好的内容传送到本地sed: stream editor流编辑器,利用命令行对文件进行修改s命令:substitution,用法:s/REGEX/SUBSTITUTION比如ssh myserver journalctl | grep ssh | grep "Disconnected from" | sed 's/.*Disconnected from //' # 删除所有'Disconnected from'提取用户名
| sed -E 's/.*?Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'排列用户名,列出用户名出现重复的次数
ssh myserver journalctl | grep sshd | grep "Disconnected from" | sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/' | sort | uniq -c其中
sort可以对输入的字符串组进行排序,uniq -c将所有重复的条目去掉,对每个条目只保留一次,并且将每个条目重复的次数打印对这个重复的次数进行排序,并打印出重复次数最多的前10个条目
| sort -nk1,1 | tail -n10sort -n将会对数字进行排列,-k1,1表明只对以空白键分割的第一列进行排序将以上筛选出的用户名以逗号分隔,打印成一行输出
| awk '{print $2}' | paste -sd,paste -s可以将多行合并为一行,-d,表明分隔符delimiter是,。awk是一种文字流处理编程语言,与sed、grep合并成为Linux三剑客,sed擅长对一行进行处理以及进行替换,grep擅长查找,awk擅长对列进行处理筛选出所有只出现过一次的名称以c开头e结尾的用户名并统计数量
| awk '$1 == 1 && $2 ~ /^c[^ ]*e$/ {print $2}' | wc -lxargs:将找到的文本作为命令行的参数rustup toolchain list | grep nightly | grep -vE "nightly-x86" | sed 's/-x86.*//' | xargs rustup toolchain uninstall有的命令可以接受标准输入作为参数,比如
grep,这样就可以使用管道命令|,比如cat /etc/passwd | grep root相当于grep root /etc/passwd,但是大多数命令不接受标准输入作为参数,只能直接在命令行输入参数,比如echo,因此xargs就是将标准输入转为命令行参数,比如$ echo "hello world" | xargs echo hello worldxargs的默认命令是echo,即xargs=xargs echo对二进制的wrangling
用ffmpeg来从摄像头捕获图像,转化为灰度图,压缩,通过ssh发送到远程服务器并在远程服务器上解压,复制并展示
ffmpeg -loglevel panic -i /dev/video0 -frames 1 -f image2 - | convert - -colorspace gray - | gzip | ssh mymachine 'gzip -d | tee copy.jpg | env DISPLAY=:0 feh -'
Exercise
查找
/usr/share/dict/words下含有至少3个a并且不以’s结尾的单词的个数grep -P "(.*a){3,}.*(?<!'s)$" /usr/share/dict/words | wc -l其中
grep -P是以perl语法输入正则表达式,以开启?<!结尾出现频率最高的两个字母是什么? 找出前三名
grep -P "(.*a){3,}.*(?<!'s)$" /usr/share/dict/words | sed -E 's/.*(\w\w)/\1/g' | uniq -c | sort -nk1,1 | tail -n3
Lecture 5 Command Line Environment
Job control
UNIX使用signal来和进程进行通信,signal起到中断作用
^C向进程发出SIGINT指令,^\向进程发出SIGQUIT指令。程序会产生core文件,相当于程序错误,kill -TERM <PID>向进程发出SIGTERM指令,该信号可以被阻塞和处理,通常用来要求程序自己正常退出,SIGSTOP是暂停进程
下述python指令将忽略^C的SIGINT指令
#!/usr/bin/env python
import signal, time
def handler(signum, time):
print("\nI got a SIGINT, but I am not stopping")
signal.signal(signal.SIGINT, handler) # attach SIGINT to handler
i = 0
while True:
time.sleep(.1)
print("\r{}".format(i), end="")
i += 1
^Z向shell发出一个SIGTSTP来暂停一个进程,使用fg或bg命令来把暂停的进程放在前台或者后台运行,比如bg %1
jobs用来列出所有当前终端对话尚未完成的任务,可以使用pgrep来获取这些任务的PID,也可以使用%1、%2等获取对这些任务的引用
可以在所有任务的最后增加一个&后缀来使命令跑在后台
直接kill %1来终止第1个任务
Terminal Multiplexers
tmux可以在一个终端窗口下使用多个pane和tab
keybinding: 默认情况下是^b。
Session:独立的工作区,
tmux:来启动一个新的sessiontmux new -s NAME:启动一个指定了名称的sessiontmux ls:列出现在的所有session- 在
tmux里按下^b d来从当前的session中detach tmux a来attach到上一个session
Windows:相当于浏览器中的tab,属于同一个session
^b ccreate一个新的窗口,通过^d来关闭这个窗口^b N前往第N个窗口,N为数字^b p前往前一个窗口^b n前往下一个窗口
Panes:相当于vim中的split界面
^b "水平分割窗口,^d退出当前窗口^b %垂直分割窗口^b <arrow>跳转窗口^b <space>在不同的窗口设计中选择
Aliases
命令的代换(aliasing)
alias alias_name="command_to_alias arg1 arg2"
注意=左右两边没有空格
e.g.
alisa ll="ls -lh"
alias gs="git status"
alias gc="git commit"
alias v="vim"
上述alias命令在shell关闭之后会自动重设,可以在.bashrc或者.zshrc中写入相关的alias来使设置永久有效
Dotfiles
很多程序使用纯文本文件dotfile来对程序进行配置,比如.vimrc,这些文件默认隐藏在目录中。对bash程序来说,.bashrc或.bash_profile是默认配置bash设置的文件。在很多程序中要求dotfile指定一个二进制可执行文件的路径
export PATH="$PATH:/path/to/program/bin"
可以将所有的dotfile放在一个文件夹下,进行版本控制,并且symlink它们,这样可以方便在不同的机器上将自定义的设置进行迁移
可以参考github上一些比较受欢迎的dotfile repo,例如https://github.com/mathiasbynens/dotfiles
为了提高dotfile的可移植性,可以在dotfile中增加一些条件判断语句,例如
if [[ "$(uname)" == "Linux" ]]; then {do_something}; fi
# Check before using shell-specific features
if [[ "$SHELL" == "zsh" ]]; then {do_something}; fi
# You can also make it machine-specific
if [[ "$(hostname)" == "myServer" ]]; then {do_something}; fi
如果想让zsh和bash使用同一个alias配置,可以在.bashrc和.zshrc文件中加入相同的
if [ -f ~/.aliases ]; then
source ~/.aliases
fi
- p.s.
source <filename>和./<filename的区别在于source是直接在当前SHELL session中执行的,而./是新起了一个session
Remote machines
SSH(secure shell)
ssh user@ip_address|url_of_server [command] # [command]表示在远程服务器中执行这个命令,然后返回到本地服务器SSH config: 客户端SSH配置文件
/etc/ssh/ssh_config。服务端SSH配置文件/etc/ssh/sshd_configSSH keys:SSH服务器持有公钥,客户端持有私钥,这样就不需要每次SSH到服务器时重新键入密码了。SSH key passphrase是为了防止别人持有你的私钥采用的加密措施
通过SSH来复制文件
最简单的方法是:
ssh+tee,e.g.cat localfile | ssh remote_server tee serverfiletee和cat正好相反,tee用于读取标准输入,将其内容输出成文件,而cat用于读取文件,将其输出成标准输出secure copy
scp:可以recurse over path,scp path/to/local_file remote_host:path/to/remote_filersync是scp基础上的提升,可以检测到本地和远程文件的相同文件,并不对它们进行重复复制。rsync的语法和scp类似
SSH port forwarding端口转发
如果在本地的应用向某个被绑定的端口发送数据,则这些数据将自动通过SSH被转发到远程服务器的另一个被绑定端口并做本地调用
Dynamic Tunneling (SOCKS proxy)
ssh -D 8080 remote_server
在192.168.56.101的浏览器中输入http://localhost时,这个http request会被发送到8080端口,但是由于SOCKS Proxy在8080端口监听,并把这个HTTP request转发给了SSH Client,SSH Client通过SSH将这个HTTP request发送给了102的SSH服务器,102在本地解析运行这个HTTP请求,由于HTTP默认使用80端口,如果102有apache绑定在其80端口上提供服务的话,那么apache服务器将接受这个对localhost的访问请求,返回相应的web服务页面
local port forwarding
ssh -L <local port>:<remote hostname>:<remote service port> user@remoteserver比如
ssh -L 8000:localhost:80 ramki@192.168.56.102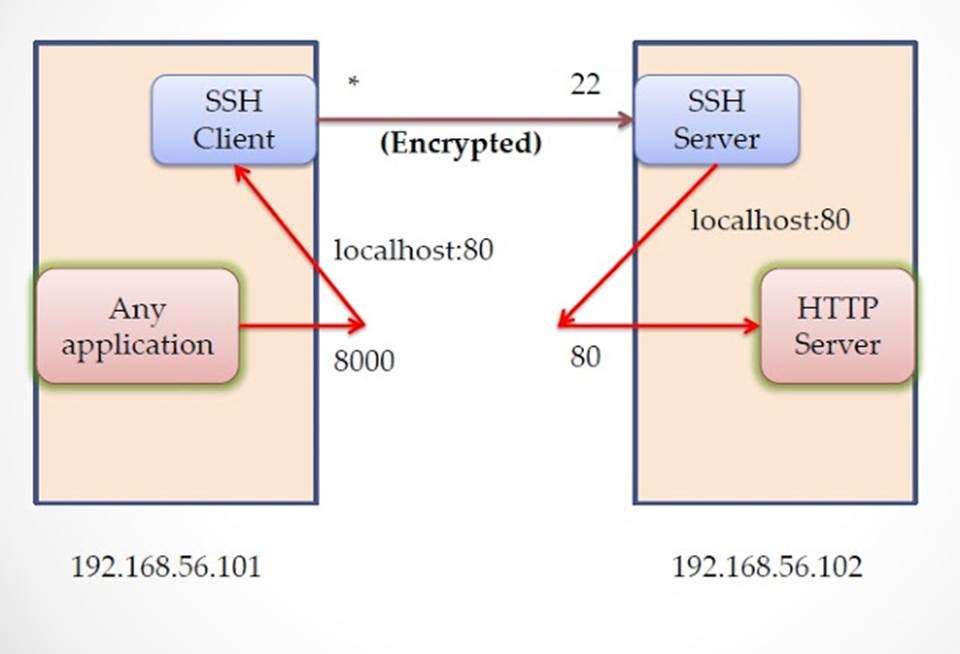
client端绑定了8000端口,任何发送到8000端口的数据都将通过SSH客户端通过22端口发送到SSH服务端,由于绑定了远程服务器的80端口,因此远程服务端将把22端口的数据转发到80端口上。在dynamic tunneling模式中,服务器会检查packet并自动决定该packet发往哪个端口,比如HTTP request发往80端口,SMTP发往25端口,但是local port forwarding将发往指定的端口
remote port forwarding
ssh -R <remote port>:<local hostname>:<local port> user@remoteserver把所有尝试发送到远程服务器指定端口的数据从<local hostname>的<local port>发送
Exercise
写一个脚本,以实现
wait [PID]的功能#!/bin/bash while : do kill -0 $1 # $1 为脚本后面跟的第一个参数,也就是PID。kill -0是尝试杀这个进程,如果这个进程不存在就会返回1,否则返回0,但是不会实际去杀掉这个进程 if [[ $? -ne 0 ]] then break fi sleep 1 done ls -al
Lecture 6 Version Control
Git data model
文件:blob,本质是
array<byte>目录:tree,本质是
map<string, blob | tree>快照(snapshot):也被称为commits,本质是被追踪的最高一级tree (root)。commits无法被改变
type commit = struct { parent: array<commit> author: string // metadata message: string // metadata snapshot: tree }历史:DAG(directed acyclic graph) of snapshots,每个历史中的snapshot都指向它们的父节点,父节点可以不止一个,因为当merge的时候就会出现两个父节点
o <-- o <-- o <-- o <---- o ^ / \ v --- o <-- o对象(object):
type object = blob | tree | commit所有对象都用SHA-1 hash来引用
objects = map<string, object> def store(object): id = sha1(object) objects[id] = object def load(id): return objects[id]git cat-file <SHA1>就相当于上面的load(id)函数引用(reference):对commit的指针(比如master),由于commit是SHA-hash码,人类难以记住,因此使用reference这种人类可读的字符串来指向commit,reference是可以改变的,即可以更改指向的commit。
references = map<string, string> def update_reference(name, id): references[name] = id def read_reference(name): return reference[name] def load_reference(name_or_id): if name_or_id in references: // is name return load(references[name_or_id]) else: // is id return load(name_or_id)HEAD:一个特殊的reference,用于指向我们目前看的commit仓库(repository):objects和references的集合
所有的
git命令都是通过加入object和加入/更新references来对DAG进行操作
Git command-line interface
基础命令
git init:创建一个新的git仓库,数据存储在.git文件夹中git status:查看目前git的状态git add <filename>:将文件添加到staging areagit commit:增加一个新的commitgit commit -a表示automatically将所有之前已经追踪过的文件进行git add,从而省去git add的步骤git log --all --graph --decorate:将git历史以DAG展现出来git log -p -2显示历史中的最后2个commit的差异(patch)git log --pretty=oneline:将每个commit的信息用一行显示过滤输出:
git log --since=2.weeks:仅打印过去2周到现在的所有commit历史--grep可以在commit信息中查找关键词进行输出过滤git log -S function_name:只显示最后一个修改了某个特定函数的commitgit log -- path/to/file:显示修改了这个文件的commitgit diff <filename>:显示某个working directory中的文件和staging area中的差异git diff --staged:显示在staging area中的文件和上次commit中的文件的差异git diff <version> <filename>:显示某个文件不同commit中的差异git checkout <version>:将HEAD移动到这个版本的commitgit rm <filename>:相当于删除某个文件,并从staging area中将其删除(但是还没有commit)如果想要在工作区中保留这个文件,但是从staging area中将其删除,使用
git rm --cached <filename>,比如git rm log/\*.log可以删除所有log/目录下的.log后缀的文件,注意要在*前加一个\号git tag:显示所有标签,git tag -l "v1.8.6*"显示所有1.8.6版本系列的标签为某一个commit创建一个新的annotated tag(一次正式的发布,包含了创建日期、名称和邮箱、GPG签名等信息):
git tag -a v1.4 -m "my version 1.4" <shachecksum>创建一个新的lightweight tag(仅仅是为一个commit对象起了一个别名,不包含任何其他信息):
git tag <tag name>默认情况下
git push时不会将tag推送到远程,可以采用git push origin --tags来将tag推送git tag -d <tag name>删除某个标签
分支和合并命令
git branch:显示目前所有的分支git branch <name>:创建一个新的分支git branch -d <name>:删除某个分支git checkout -b <name>:创建一个新的分支并且切换到这个分支,相当于git branch <name>; git checkout <name>,可以用git switch -c <name>代替git merge <revision>:将<revision>合并到当前分支git mergetool:使用合并工具来帮助处理合并冲突git rebase:也可以达到合并分支的效果,但是和merge不同的是分叉会被取消
git merge:origin和mywork产生了分叉
git rebase:没有分叉,Commit5’和6‘以补丁的形式存在,放在./git/rebase目录中
远程命令
origin是默认的被克隆的远程名称(不是分支名,origin的master分支为origin/master),被track的上游远程分支可以以@{upstream}或@{u}指代
git remote:显示所有已知的远程,增加一个-vflag来显示远程仓库的URL,或者git remote show <remote>来显示更多信息git remote add <name> <url>:增加一个新的远程git remote rm <name>:删除某个远程git push <remote> <local branch>:<remote branch>:将objects发送到远程分支,并且更新远程分支的referencegit push <remote> --delete <remote branch>:删除远程分支git branch --set-upstream-to=<remote>/<remote branch>:设置本地branch和远程branch的连接关系,从而可以直接进行git push而不需要指定远程branchgit branch -vv查看目前正在追踪的远程分支git fetch:从远程项目拉取所有的objects/reference,但是并不merge到working directory中,对working directory没有任何影响git pull:相当于git fetch; git mergegit clone:从远程分支下载repo,将本地的master分支追踪远程的master分支(本地分支和远程分支存在连接关系,运行git push时本地分支将知道push到哪个远程分支)git rebase:将一个分支rebase到另一个分支上,这样可以使分叉的commit变成线性的
撤销命令
所有的commit大概率是可以被恢复的,但是没有被commit的snapshot很难被恢复
git commit --amend:修改commit的内容比如
git commit -m 'Initial commit' git add forgotton_file git commit --amend最终只有一个initial commit,里面包括了forgotton_file
git reset HEAD <file>:把文件从staging area撤出,但是不会修改文件也可以使用
git restore --staged <file>git restore <file>则是将还未stage的文件恢复到上一次commit时的状态git checkout -- <file>:把文件在工作区的修改全部撤销,撤销到最近一次git commit或git add的状态。当文件自修改后还没有放到暂存区时,使用本命令将回到和版本库相同的状态(但git还是知道修改的),当文件已经添加到暂存区,并且又做了修改之后,则回到添加到暂存区时的状态。
高级命令
git config:配置git,分成三个层面的配置,包括系统级别、用户级别、仓库级别git config --system -l查看系统配置,配置文件存储于[path]/etc.gitconfiggit config --global -l查看用户配置,配置文件存储于~/.gitconfig或~/.config/git/config文件git config --local -l查看仓库配置,配置文件存储于[repo]/.git/config优先级:仓库配置>用户配置>系统配置
设置
main为默认的分支名:git config --global init.defaultBranch maingit clone --depth=1:浅克隆,将忽略之前所有的版本历史git add -p:交互式添加到暂存区,能够方便地将一个文件中的部分内容添加到暂存区git rebase -i:interactive rebasinggit blame:显示哪个用户编辑了哪一条git stash:将目前还不想提交但是已经修改的内容(包括工作区和暂存区)保存到堆栈中,后续可以在某个分支上恢复出堆栈的内容。git stash pop将堆栈中的内容弹出到当前分支上,堆栈内容被删除,而git stash apply则将堆栈中的内容应用到当前分支上,和git stash pop不同的是堆栈中的内容并不会被删除,适用于应用到多个分支的情况.gitignore:指定不需要track的文件
Git workflow
https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow
软件开发的workflow,规定了分支的类型和怎样合并分支
master分支:软件的release版本分支
develop分支:开发分支
feature分支:每个单独的feature作为一个分支,以develop作为父分支
- 推荐阅读:pro git
Lecture 7 Debugging and Profiling
Logging
Linux终端显示不同的颜色,使用ANSI escape颜色码
echo -e "\e[1;31mThis is red\e[0m"显示红色的This is redecho -e "\e[1;42mGreen Background\e[0m"显示绿色背景的Green Background大多数程序将日志文件存放在
/var/log目录下,systemd是一个system的daemon程序,将所有系统日志存放在var/log/journal下,可以用journalctl来查看logger "logging info"可以将log记录到journal中
Debugging
pdb:python debugger
- s(tep):单步执行,相当于step into
- n(ext):单步执行,相当于step over
- l(ist):列出执行到的那行代码的前后十一行
- c(ontinue):继续执行,直到遇到下一条断点
- b(reakpoint):设置断点
- cl(ear):清除断点
- r(eturn):执行当前运行函数直到结束
- p(rint) <expression>:输出expression的值
- q(uit):退出debugger
- restart:重新debug
使用python -m pdb <filename.py>来进行pdb调试,其中-m表示将模块(module)当作脚本运行,也就是将pdb当作脚本运行
gdb(GNU debugger):C/C++ debugger,也支持Go和Rust调试,用法和pdb类似
静态代码分析:无需用编译器编译运行即可扫描出代码错误
pyflakes是python的静态扫描工具,shellcheck可以对shell scripts进行扫描
code linting:在编译前即标出警告和错误的位置
一些linter推荐:
https://github.com/caramelomartins/awesome-linters#cc
Profiling
获取程序运行的资源占用以及时间信息
Timing
- Real time: 真实时间,包括了被其他进程占用的时间和等待I/O以及网络的时间
- User time: 用户时间,即CPU运行用户代码所花费的时间
- Sys time: 系统时间,即CPU运行kernal代码所花费的时间
time <command>可以计算上述三个时间
CPU profiler
最常见的profiler,两种类型:
- tracing profiler: 记录每个函数调用
- sampling profiler:周期性地对程序采样,记录程序的堆栈
对于python程序,使用cProfile来作为profiler
python -m cProfile -s tottime <filename.py>
但是由于cProfiler将所有内部调用函数的开销都统计在内,很难看出真正把时间都花在了哪里,因此可以使用line_profiler来统计每一行代码所花费的时间,这样更加直观,需要添加一个decorator @profile来声明需要进行profiling的函数
可以使用flame graph来将CPU profiling可视化
memory profiler
内存泄漏:即使在不需要用到这些内存的时候也不将其释放,在没有垃圾收集的语言,比如C/C++中可以使用valgrind来显示内存泄漏,python可以使用memory_profiler来进行memory profiling
- 函数调用图:python中可以选择
pycallgraph来显示哪个函数调用了哪个
resource monitoring
htop:top的升级版,来观察系统资源使用情况
free:观察系统可用内存使用情况
df:当前文件夹中磁盘使用情况
nethogs/iftop/ss:网络使用情况
hyperfine:对程序进行快速benchmark,例如比较fd和find的速度
hyperfine --warmup 3 'fd -e jpg' 'find . -iname "*.jpg"'
Lecture 8 Metaprogramming
Build systems
将依赖编译构建为二进制文件的流程需要用到build systems,比如make
定义:
- 依赖(dependency)
- 目标(target)
- 构建规则(rule)
在某个目录下执行make时,make将会查找该目录下的Makefile,示例如下所示
# this is comment
@# @ is to turn off the echoing of comment
# .ONESHELL:
paper.pdf: paper.tex plot-data.png
pdflatex paper.tex plot-data.png
plot-%.png: %.dat plot.py
./plot.py -i $*.dat -o $@
冒号左边是需要构建的目标文件,冒号右边是依赖文件,下面一行是构建规则,,注意每行命令在单独的shell中执行,这些shell之间没有继承关系,除非将几行命令写在一行中,中间用分号分割,或者加上.ONESHELL:命令,每一个这样的组合构成了一个directive %是一个样式,匹配任意字符串,如果需要构建的是plot-data.png,那么就会去寻找data.dat这个依赖文件
$@是目前的target
目标文件如果已经构建成功,而依赖文件没有作任何更新,那么再执行make将不会有任何动作,如果某个依赖文件更新,那么只对和该依赖文件有关的编译动作进行重新编译。
除了文件名,目标还可以是某个操作的名字,称为伪目标,比如make clean不是make一个叫做clean的文件,而是删除对象文件,因此要把clean声明为伪目标
.PHONY: clean
clean:
rm *.o temp
make install将可执行文件复制到正确的路径,即被复制到某个PATH包含的路径
Dependency management
有多种不同的依赖:
依赖程序:例如
python依赖系统包(system packages):例如
openssl编程语言中的库(library):例如
matplotlib仓库:管理各种依赖的地方,比如ubuntu中的
apt、Ruby中的gem、Python中的pip以及nodejs中的npm
versioning:对软件版本控制
semantic versioning: major.minor.patch
- patch:新的版本不改变API,增加patch#
- minor:如果对API的改变是向后兼容的,增加minor#
- major:如果对API的改变不向后兼容,增加major#
lock file:列出所有依赖的版本信息的文件,需要手动对依赖库中的软件进行升级
vendoring:将所有依赖的源代码复制到项目中,来获得对依赖的完全控制权
Continuous Integration System (CI)
持续集成,即一旦进行了源代码的commit,即进行自动编译测试,将代码集成到主干,从而尽快发现错误,防止分支大幅偏离主干
比较多的CI工具包括Travis CI、Azure Pipelines和Github Actions
CI是事件触发,一旦被触发,CI将起一个虚拟机,在其中运行用户规定的recipe所需要执行的命令。GitHub Pages就是一个CI系统,每次md文件被commit到repo后jekyll就会将其编译为HTML并deploy到服务器上
git本身就是一个简单的CI系统,在.git/hooks下有一些事件触发的脚本,比如pre-commit.sample,在commit时被触发
测试
- test suite:所有测试的集合
- unit test:单元测试,对某一个feature进行单独测试
- integration test:集成测试,对各个单元继续联合测试
- regression test:回归测试,对之前所有产生bug的条件进行测试从而保证相同的bug不再出现
- mocking:用一个假的Implementation来代替一个功能模块来实现对其他依赖于此模块的其他模块进行测试
Lecture 9 Security and Cryptography
Hash functions
将一个任意长度的bytes array映射到一个固定长度的byte
其中一种Hash function是SHA1,生成160位输出(40个16进制字符)
可以使用sha1sum命令来输出一个文件的SHA1哈希值
哈希函数有以下的特性:
- deterministic:相同的输入总是生成相同输出
- non-invertible:已知输出,很难得到输入
- collision resistant:两个不同的输入很难得到相同的输出
Key Derivation Functions (KDF)
本质上属于Hash函数
给一个passphrase(相当于用户的password),生成一个固定长度的key,通常KDF相当缓慢,为了防止brute force破解密码
KDF可以用于存储网站密码,比如生成一个随机的salt,然后存储salt以及KDF(password+salt),用重新生成KDF(password+salt)来验证每次的登陆尝试
Symmetric cryptography
对称加密的过程:
keygen() -> key # 随机生成一个key,通信双方交换这个key,key需要保密
encrypt(plaintext, key) -> ciphertext
decrypt(ciphertext, key) -> plaintext
对称加密的特性:
- 即便拥有ciphertext,没有key的情况下也无法得到plain text
- 显然正确性,即
decrypt(encrypt(message, key), key) = message
比较著名的对称加密算法:AES
Asymmetric cryptography
非对称加密,有一个公钥,不需要保密,还有一个私钥,自己保存,需要保密。这样可以解决对称加密中需要交换密钥的问题
非对称加密的过程:
keygen() -> (public key, private key)
encrypt(plaintext, public key) -> ciphertext
decrypt(ciphertext, private key) -> plaintext
非对称加密可以用于签名/验证过程:
sign(message, private key) -> signature
verify(signature, message, public key) -> <bool>is_signature
非对称加密的应用:
- PGP邮件加密
- 私人通信频道
公钥分发:如何确认别人得到的公钥确实是我们给他们的公钥?
著名的非对称算法:RSA算法
GPG(GNU Private Guard)是一个使用RSA算法对文件进行加密的软件
使用方法:https://www.digitalocean.com/community/tutorials/how-to-use-gpg-to-encrypt-and-sign-messages
case study
Two-Factor Authentication (2FA):用一个passphrase和某个authenticator(授权文件或物理设备,如YubiKey)来防止passphrase的泄露
磁盘加密:使用对称加密,需要passphrase,Linux上可以使用cryptsetup+LUKS,Windows上可以使用BitLocker
SSH:
ssh-keygen是非对称加密,生成一个公钥和密钥,密钥采用KDF进行对称加密,因此需要一个passphrase。服务器需要知道公钥,私钥保存在本地。服务器先选一个随机的信息发送给client,要求client对该信息进行签名,client将该信息签名之后发送给server,server通过公钥验证该签名
Lecture 10 Miscellaneous
Daemons
守护进程,开机自动运行在后台的进程,这些进程一般后缀都有一个d,比如
sshd就是SSH的守护进程,负责监听SSH请求。systemd是linux的系统守护进程,负责运行和设置守护进程,可以运行systemctl status来列出当前正在运行的daemon。可以使用cron来定时运行守护进程FUSE (Filesystem in User SpacE)
用户空间文件系统,即用户可以通过FUSE在用户空间定制实现自己的文件系统而不必在内核态
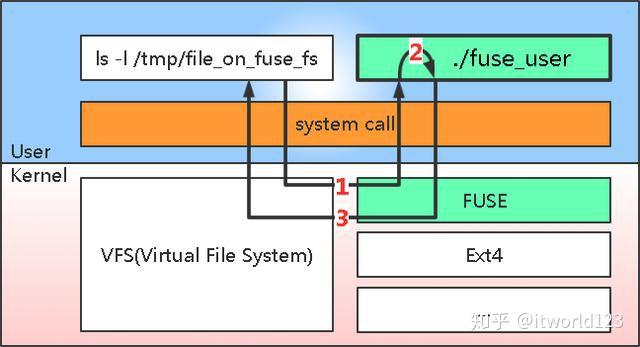
fuse_user是开发的用户态的文件系统程序,该程序启动的时候会将自己开发的接口注册到fuse中,比如读写文件的接口,遍历目录的接口等等。 同时,通过该程序在系统某个路径挂载fuse文件系统,比如/tmp/file_on_fuse_fs。此时如果在该目录中有相关操作时,请求会经过VFS到fuse的内核模块(上图中的步骤1),fuse内核模块根据请求类型,调用用户态应用注册的函数(上图中步骤2),然后将处理结果通过VFS返回给系统调用(步骤3)。
SSHFS就是一个FUSE文件系统,可以通过SSH链接在本地打开远程服务器的文件/文件夹API
大多数的线上服务有可以让你通过编程获取一定形式的API,这些API都有固定结构的URL,经常是以
api.service.com为root很多API会要求一个token来获取服务,可以通过
OAuth这个协议来获取tokentoken和密码是不同的,token是短期的,到期自动失效,也可以被数据所有者撤销,且有权限范围
Command Line flags/patterns
大多数命令行有类似的flag,比如:
- dry run:只会打印出如果不在dry run模式下的结果,但实际上什么修改都不会进行
--verbose或-v:打印详细内容,-vvv打印更详细的内容,--quiet打印简短的内容-代替文件名表示标准输入输出--表示停止将后面的字符以flag对待,比如rm -- -r就是删除-r这个文件而不是进行递归删除
tiling window manager
瓦片窗口管理器,窗口永远平铺,很多使用Lua进行编程
Linux快捷键
^l:清屏
^u:删除光标前的全部指令
Linux安装必需的包:
gcc
sudo apt update sudo apt-get install build-essential